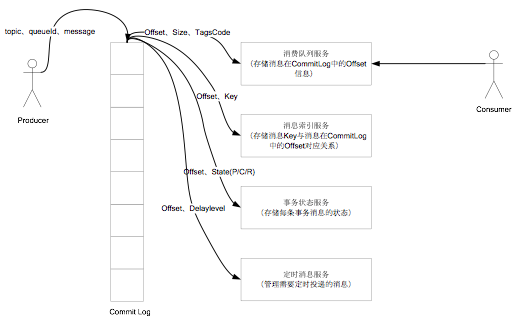
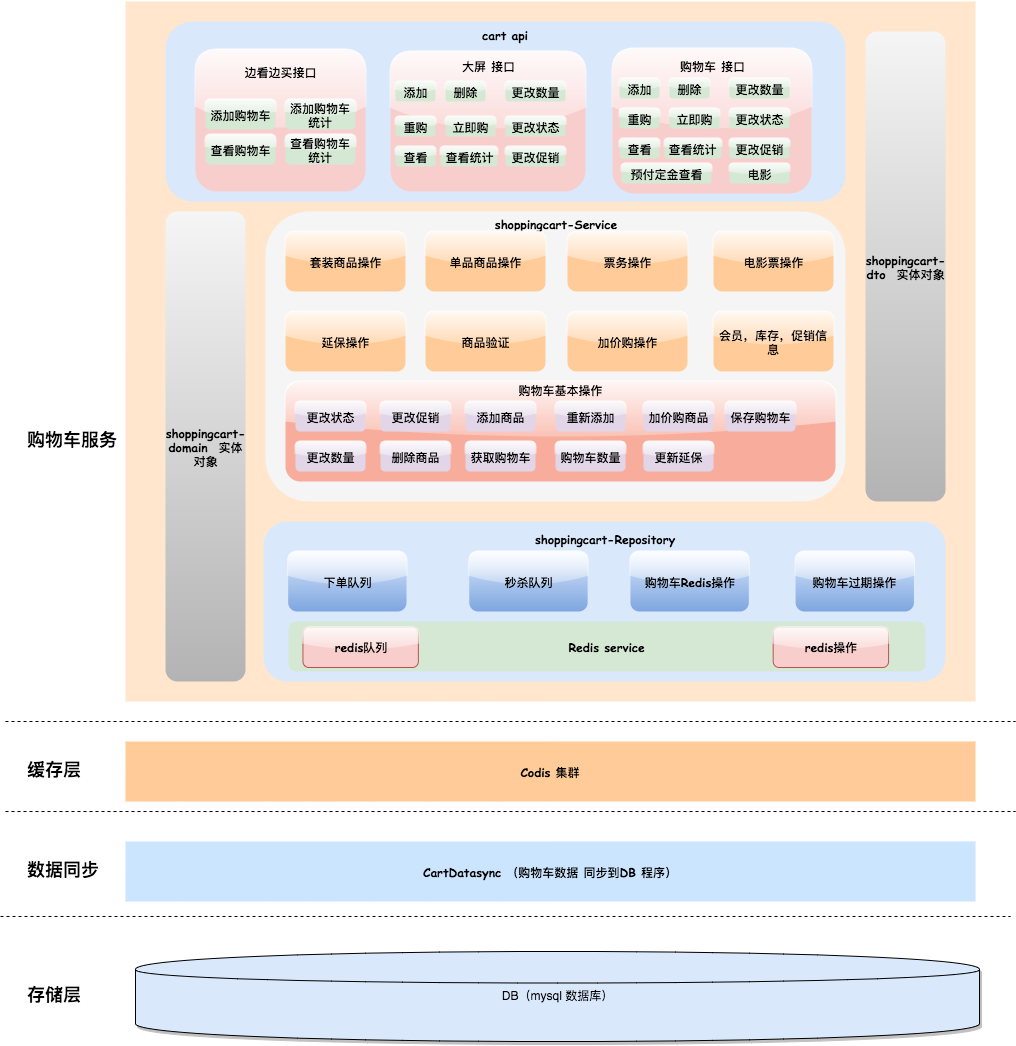
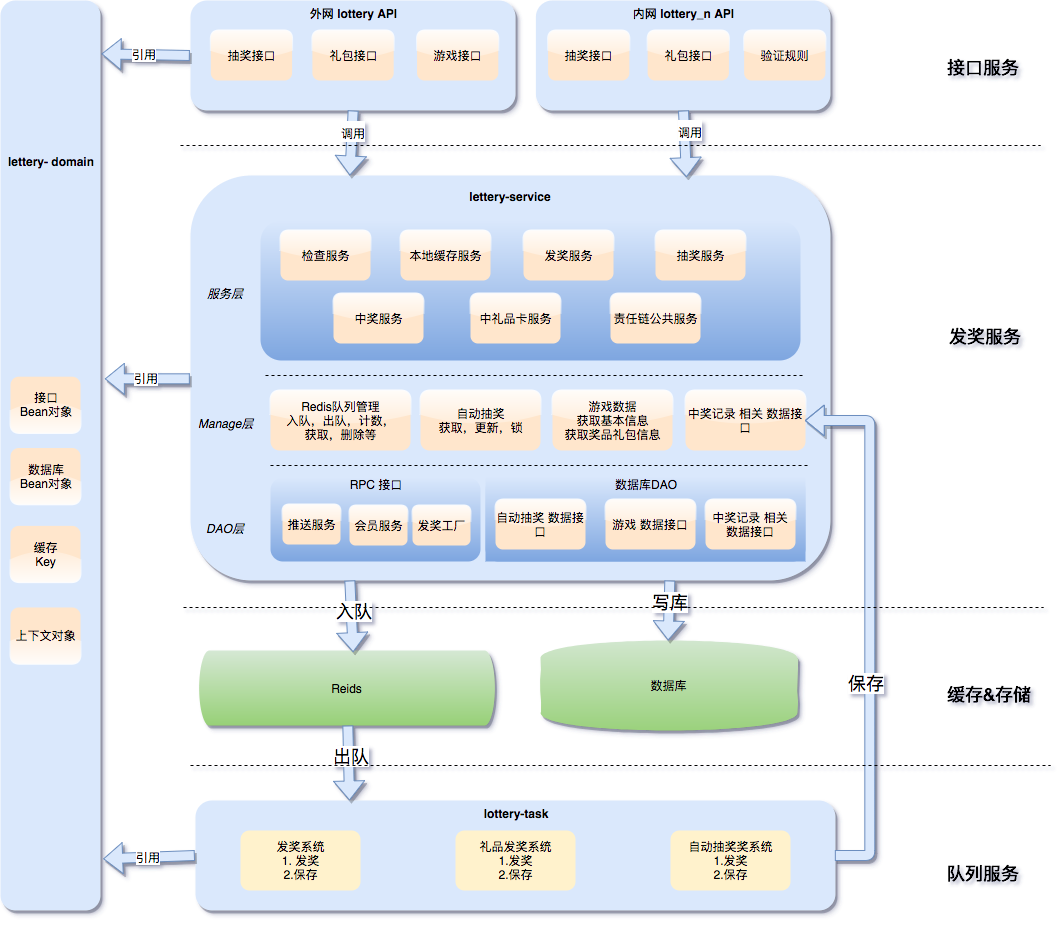
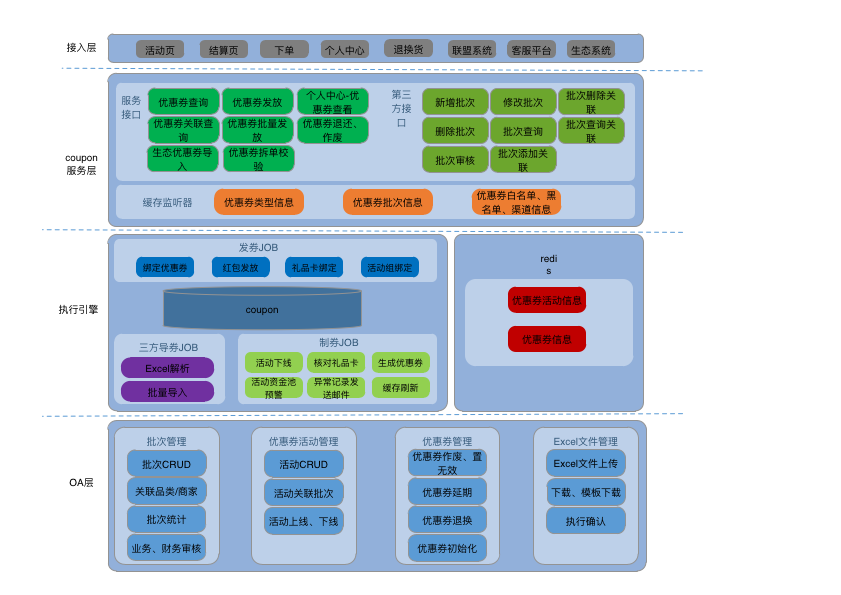
maven聚合项目通过deploy打包自己的项目到远程库时,出现了” Failed to read artifact descriptor for XX,Could not find artifact XX “ 这样的信息,导致编译失败。
但是在本地install的时候却是成功的。也就是说,项目在本地跑什么事没有,一旦发布自己的jar包就不行。
根据错误信息提示,最后,将问题定位在一个依赖的外部jar包,发现只要把这个jar包的依赖注解掉,项目发布就没问题,但是加上就报错。
解决办法:问题的原因是因为依赖的jar,其deploy方式有问题。
如果是一个单独的maven项目,其发布方式:1
2mvn -U clean install -Dmaven.test.skip=true
mvn -U clean deploy -Dmaven.test.skip=true
但如果是一个maven的聚合项目,只想发布部分module:1
2
3mvn -U clean install -Dmaven.test.skip=true
mvn -U clean deploy -Dmaven.test.skip=true -pl :xxx1 -am
mvn -U clean deploy -Dmaven.test.skip=true -pl :xxx2 -am
其中,xxx1、xxx2是module的名字,注意一定不要忽略-am这个参数,否则就会出现,我上面描述的问题。
-am参数表示构建指定模块,同时构建指定模块依赖的其他模块。(全称also make)